Week 3-3 of the AWS MLops: Computer vision and AWS Rekognition
Computer Vision and Amazon Rekognition#
Computer vision#
- Automated extraction of information from digital images
- Applications
- Public safety and home security
- Authentication and enhanced computer-human interaction
- Content management and analysis
- Autonomous driving
- Medial imaging
- Manufacturing process control
- Computer vision problems:
- Image analysis
- Object classification
- Object detection
- Object segmentation
- Video analysis
- Instance tracking, pathing
- Action recognition
- Motion estimation
- Image analysis
Amazon Rekognition#
Managed service for image and video analysis
Types of analysis:
- Searchable image and video libraries
- Face-based user verification
- Sentiment and demographic analysis
- Unsafe content detection
Can add powerful visual analysis to application
Highly scalable and continuously learns
Integrates with other AWS services
Examples:
- Searchable image library
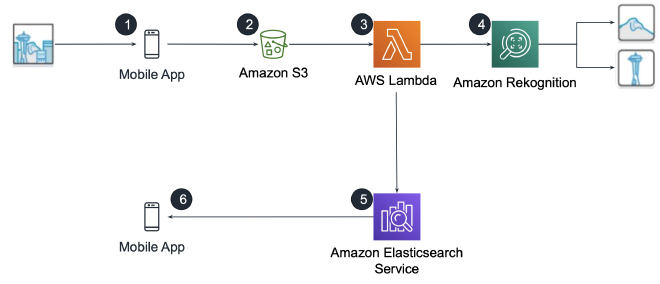
</figure>- Image moderation
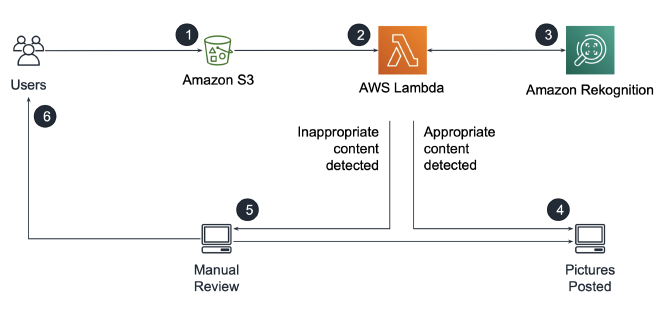
</figure>- Sentiment analysis
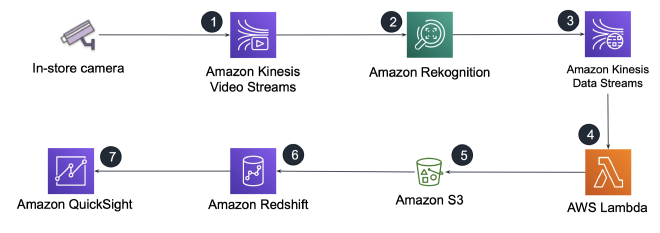
</figure>- AWS services used in these examples:
- S3
- Lambda
- Rekognition
- Elasticsearch Service
- Kinesis Video Streams
- Kinesis Data Streams
- Redshift
- QuickSight
Custom Labels#
- Example use cases
- Search logos
- Identify products
- Identify machine parts
- Distinguish between healthy and infected plants
- Almost all vision solutions start with an existing model
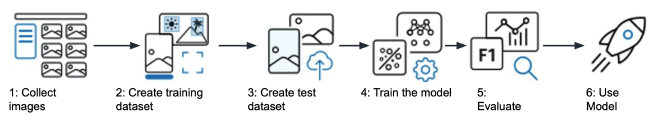
- Custom labeling process
- Collect images
- Collect few hundred images
- Build domain-specific models
- 10 PNG or JPEG images per label
- Use images similar to the images that you want to detect
- Create dataset
- Images, labels, and bounding boxe
- Need at least two labels
- Label images by using console or Amazon Sagemaker Ground Truth
- Model evaluation
- Precision, recall
- Overall model performance
- Improve the model
- Better and more data
- Reduce false positives (better precision): could add more classes as labels for training
- Reduce false negatives (better recall): use better data or more precise classes (labels) for training
- Adjust the confidence threshold to tune precision/recall
- Use model
- Apply the model on new images and collect custom labels: label, object bounding box, and confidence level
- Collect images