Week 3-2 of the AWS MLops: AWS Forecast and time-series data
Forecasting and AWS Forecast#
Overview#
- Predicting future values that are based on historical data
- Patterns include
- Trends
- Seasonal, pattern that is based on seasons
- Cyclical, other repeating patterns
- Irregular, patterns that might appear to be random
- Examples
- Sales and demand forecast
- Energy consumption
- Inventory projections
- Weather forecast
Processing time series data#
Time series data is captured in sequence over time
Handle missing data
- Forward fill
- Backward fill
- Moving average
- Interpolation: linear, spline, or polynomial
- Sometimes zero is a good fill value
Reasmpling: Resampling time series data allows the flexibility of defining resolution of the data
- Upsampling: increase the sample frequency, e.g. from minutes to seconds. Care must be taken in deciding how the fine-grained samples are computed.
- Downsampling: decrease the sample frequency, e.g. from days to months. Need to pay attention to how the aggregation is carried out.
- Reasons for resampling:
- Inspect the behavior of data under different resolutions
- Join tables with different resolutions
Sampling smoothing, including outlier removal
- Why
- Part of the data preparation process
- For visualization
- How does smoothing affect the outcome
- Cleaner data to model
- Model compatibility
- Production improvement?
- Why
Seasonality
- Hourly, daily, quarterly, yearly
- Spring, summer, fall, winter
- Holidays
Time series sample correlations
- Stationary
- How stable is the system
- Does the past inform the future
- Trends
- Correlation issues
- Autocorrelation
- How points in time series sample are linearly related
- Stationary
pandasoffer many methods for handling time series data- Time-aware index
groupbyandresample()autocorr()method
Times series algorithms offered by Amazon Forecast
- ARIMA, autoregressive integrated moving average
- DeepAR+
- Exponential Smoothing (ETS)
- Non-Parametric Time Series (NPTS)
- Prophet
Model evaluation
- Time series data model training cannot use $k$-fold cross validation because the data is ordered and correlated.
- Standard approach: back testing
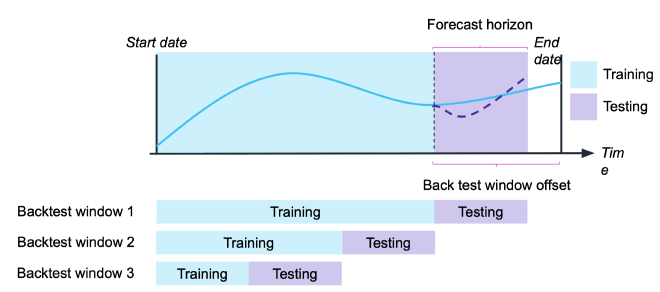
</figure>- Two metrics can be used to access the backtesting (hindcasting instead of forecasting) accuracy
- wQuantileLoss: the average error for each quantile in a set
- RMSE, root mean square error