Week 1-3 of the AWS MLops: Data ingestion and AWS jobs
AWS job styles:#
- Batch
- Glue: creates metadata that allows to perform operations on e.g. S3 or a database. This is a serverless ETL system.
- Batch: general purpose batch, can process anything at scale in containers and training models with GPUs.
- Step functions: parameterize different steps, orchestrate Lambda functions with inputs.
- Streaming
- Kinesis: send in small payloads and process them as it receives the payloads.
- Kafka via Amazon MSK
In terms of operation complexity and data size, here is a high level comparison
| Batch | Streaming | |
|---|---|---|
| complexity | simple | complex |
| data size | large | small |
- Complexity: Batch jobs are simpler, they receive data, execute operations across, then give back results. Streaming jobs on the other hand need to take in data as they come in and a bit more prone to error and mistake.
- Data size: Batch jobs are good at handling large data payloads since they are designed to process in batch. While streaming jobs process things as they come in.
Batch: data ingestion and processing pipelines#
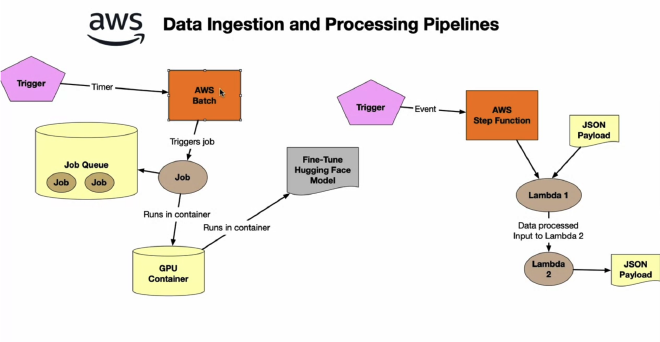
Examples#
- Example 1 - AWS Batch:
- Event trigger creates new jobs
- New jobs are stored in queue. Can have thousands of jobs.
- Each job launches its own container and performs things like fine tuning Hugging Face models using GPUs.
- Example 2 - AWS Step Function:
- Event trigger
- First step, a Lambda function, gets JSON payload and exports results.
- Second step, also a Lambda function, takes outputs from the previous step as inputs. Exports results as JSON.
- Example 3 - AWS Glue, an ETL pipeline:
- Event trigger
- AWS Glue points to multiple data sources: CSV files in S3 or external PostgreSQL database.
- Glue ties multiple data sources together and creates an ETL then transform the data and put it into a S3 bucket.
- Glue creates a data catalog that can be queried via AWS Athena without having to actually pull all the data out of S3 for data visualization and maybe manipulation.